Đạo hàm của tất cả các lớp
Đạo hàm theo các tham số riêng lẻ
Trong bước lan truyền thuận, với giá trị đầu vào x, đầu ra của mạng neural được tính toán. Trong quá trình này, các giá trị kích hoạt tại mỗi lớp được lưu lại để sử dụng sau.
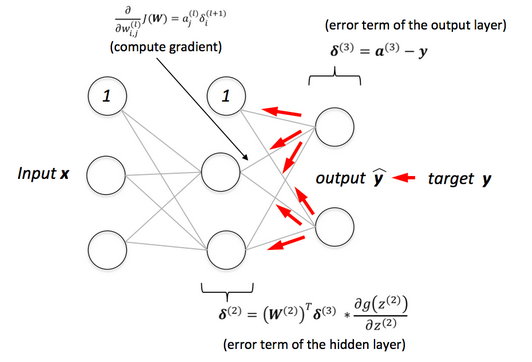
Với mỗi đơn vị j trong lớp đầu ra, tính toán sai số:
Từ đây, chúng ta có thể suy ra:
Với các lớp , chúng ta tính toán:
Cập nhật đạo hàm cho mỗi tham số sẽ là:
Đạo hàm theo các ma trận
Việc tính toán đạo hàm cho từng tham số riêng lẻ như đã mô tả ở trên rất dễ để hiểu. Tuy nhiên, trong thực tế, chúng ta cần tối ưu hóa các phép tính bằng cách diễn tả chúng dưới dạng vector và ma trận để tăng tốc độ thuật toán. Ta định nghĩa:
Bước lan truyền thuận: Với giá trị đầu vào được cho, tính toán đầu ra của mạng đồng thời lưu lại các giá trị kích hoạt tại mỗi lớp.
Với lớp đầu ra, tính toán:
Từ đây, ta suy ra:
Với các lớp :
Ở đây, là tích Hadamard (tích từng phần tử), nghĩa là mỗi thành phần của hai vector sẽ được nhân với nhau để tạo ra một vector kết quả.
Cập nhật đạo hàm cho các ma trận trọng số và vector bias
Lưu ý: Biểu thức đạo hàm ở dòng trước có thể gây ra câu hỏi: tại sao lại là mà không phải là hoặc cách khác? Một quy tắc quan trọng cần nhớ là kích thước của hai ma trận ở phía bên phải phải khớp nhau. Kiểm tra điều này cho thấy rằng vế trái biểu diễn đạo hàm với ma trận , có kích thước . Do đó, và có nghĩa là biểu thức đúng phải là . Hơn nữa, đạo hàm của một hàm số có giá trị vô hướng với một ma trận sẽ có kích thước tương ứng với ma trận đó.
Lan truyền ngược cho Gradient Descent theo Mini-Batch
Điều gì xảy ra khi chúng ta muốn triển khai Gradient Descent theo mini-batch? Trên thực tế, Mini-batch Gradient Descent là phương pháp được sử dụng phổ biến nhất. Khi tập dữ liệu nhỏ, Gradient Descent theo batch có thể được áp dụng trực tiếp.
Trong trường hợp này, cặp sẽ ở dạng ma trận. Giả sử rằng mỗi lần tính toán xử lý điểm dữ liệu. Khi đó, ta có:
trong đó là kích thước của dữ liệu đầu vào (không bao gồm bias).
Do đó, các giá trị kích hoạt sau mỗi lớp sẽ có dạng:
Ta có thể suy ra các công thức cập nhật như sau.
Bước lan truyền xuôi: Với toàn bộ tập dữ liệu (batch) hoặc một mini-batch của đầu vào , tính toán đầu ra của mạng đồng thời lưu lại các giá trị kích hoạt tại mỗi lớp. Mỗi cột của tương ứng với một điểm dữ liệu trong .
Với lớp đầu ra, tính toán:
Từ đây, ta suy ra:
Với các lớp :
Ở đây, chỉ tích từng phần tử, nghĩa là mỗi phần tử của hai ma trận sẽ được nhân để tạo ra ma trận kết quả.
Cập nhật đạo hàm cho các ma trận trọng số và vector bias:
Phương pháp lan truyền ngược có cấu trúc này, dù là cho Gradient Descent ngẫu nhiên hay theo batch, không chỉ nâng cao sự hiểu biết mà còn tối ưu hóa hiệu quả tính toán trong việc huấn luyện mạng neural.