Mạng nơ-ron nhiều lớp (MLP)
Giới thiệu về Mạng nơ-ron nhân tạo (ANN)
Mạng nơ-ron nhân tạo (ANN) là một trong những khái niệm cơ bản trong các lĩnh vực trí tuệ nhân tạo (AI) và học máy. Được lấy cảm hứng từ cấu trúc và chức năng của hệ thần kinh trong não người, ANNs là những mô hình tính toán có khả năng học hỏi từ dữ liệu và cải thiện hiệu suất theo thời gian. Chúng đã trở thành nền tảng của nhiều công nghệ hiện đại, bao gồm nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên và xe tự lái, ...
Nguồn gốc của mạng nơ-ron nhân tạo
Khái niệm về ANN bắt nguồn từ chức năng của các nơ-ron sinh học trong não người. Mô hình nơ-ron nhân tạo đầu tiên, được gọi là "Perceptron," được phát triển vào năm 1958 bởi nhà khoa học Frank Rosenblatt. Mặc dù Perceptron ban đầu chỉ có thể giải quyết các bài toán tuyến tính, nó đã mở đường cho việc khám phá các mô hình phức tạp hơn, dẫn đến sự phát triển của các mạng nhiều lớp và các thuật toán học sâu hiện đại.
Vấn đề mà ANN giải quyết
ANN thường được áp dụng cho các bài toán liên quan đến phân loại, dự đoán và nhận diện mẫu. Một vấn đề điển hình mà ANNs giải quyết là phân loại hình ảnh: hệ thống học từ các hình ảnh có nhãn và sau đó dự đoán nhãn của các hình ảnh mới. ANNs cũng được sử dụng trong các nhiệm vụ tối ưu hóa, phân tích hồi quy và dự đoán chuỗi thời gian.
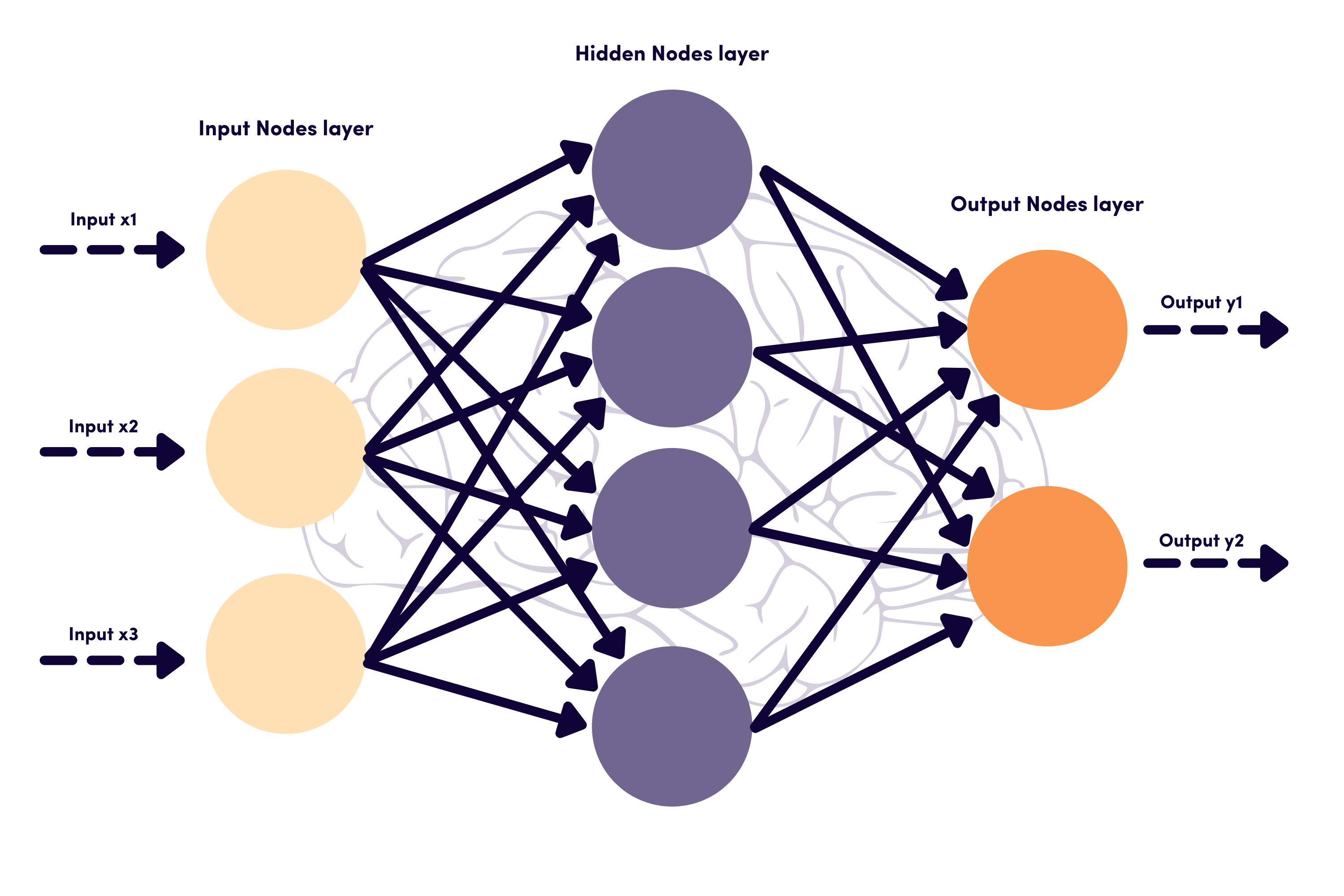
Các lớp trong ANN
Một Mạng nơ-ron nhân tạo bao gồm nhiều lớp làm việc cùng nhau để xử lý và trích xuất thông tin từ dữ liệu:
-
Lớp đầu vào: Đây là lớp đầu tiên nhận dữ liệu đầu vào. Mỗi nơ-ron trong lớp này đại diện cho một đặc trưng của dữ liệu.
-
Lớp ẩn: Nằm giữa lớp đầu vào và lớp đầu ra. Các lớp này trích xuất các đặc trưng từ dữ liệu bằng cách sử dụng các hàm kích hoạt như ReLU (Rectified Linear Unit) hoặc Sigmoid.
-
Lớp đầu ra: Lớp cuối cùng tạo ra các kết quả dự đoán dựa trên thông tin đã được xử lý trong các lớp ẩn. Số lượng nơ-ron trong lớp này phụ thuộc vào bài toán hiện tại (ví dụ, nếu nhiệm vụ phân loại có ba danh mục, lớp đầu ra sẽ chứa ba nơ-ron).
Các hàm kích hoạt trong ANN
Các hàm kích hoạt đóng vai trò quan trọng trong việc xác định đầu ra của các nơ-ron trong ANN. Dưới đây là một số hàm kích hoạt phổ biến:
-
ReLU (Rectified Linear Unit): Hàm ReLU được định nghĩa như sau:
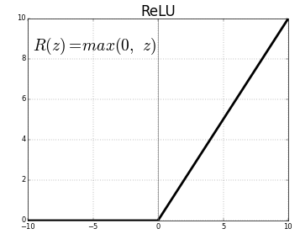
Hàm này được sử dụng rộng rãi trong các lớp ẩn nhờ tính đơn giản và hiệu quả. Ta thấy rằng, khi đạo hàm hàm ReLU, với x < 0 thì f'(x) = 0 và x > 0 thì f'(x) = 1. ReLU cho phép các giá trị dương đi qua trong khi chặn các giá trị âm, dẫn đến việc hội tụ nhanh hơn trong quá trình huấn luyện.
-
Sigmoid: Hàm Sigmoid được định nghĩa như sau:

Hàm này nén các giá trị đầu vào vào khoảng giữa 0 và 1, làm cho nó phù hợp cho các nhiệm vụ phân loại nhị phân. Tuy nhiên, nó có thể dẫn đến tiêu giảm cho các đầu vào dương hoặc âm lớn, điều này có thể cản trở quá trình học trong các mạng sâu hơn.
-
Tanh (Hyperbolic Tangent): Hàm Tanh được định nghĩa như sau:

Nó xuất ra các giá trị nằm giữa -1 và 1, giúp trung tâm hóa dữ liệu quanh zero. Tanh thường hoạt động tốt hơn so với hàm Sigmoid, vì nó giảm thiểu vấn đề gradient biến mất ở mức độ lớn hơn.
-
Softmax: Hàm Softmax thường được sử dụng trong lớp đầu ra của các bài toán phân loại đa lớp. Nó chuyển đổi các điểm số thô (logits) từ mạng thành xác suất tổng bằng 1, làm cho nó phù hợp với các mô hình cần dự đoán xác suất của mỗi lớp. Công thức của hàm Softmax được cho bởi:
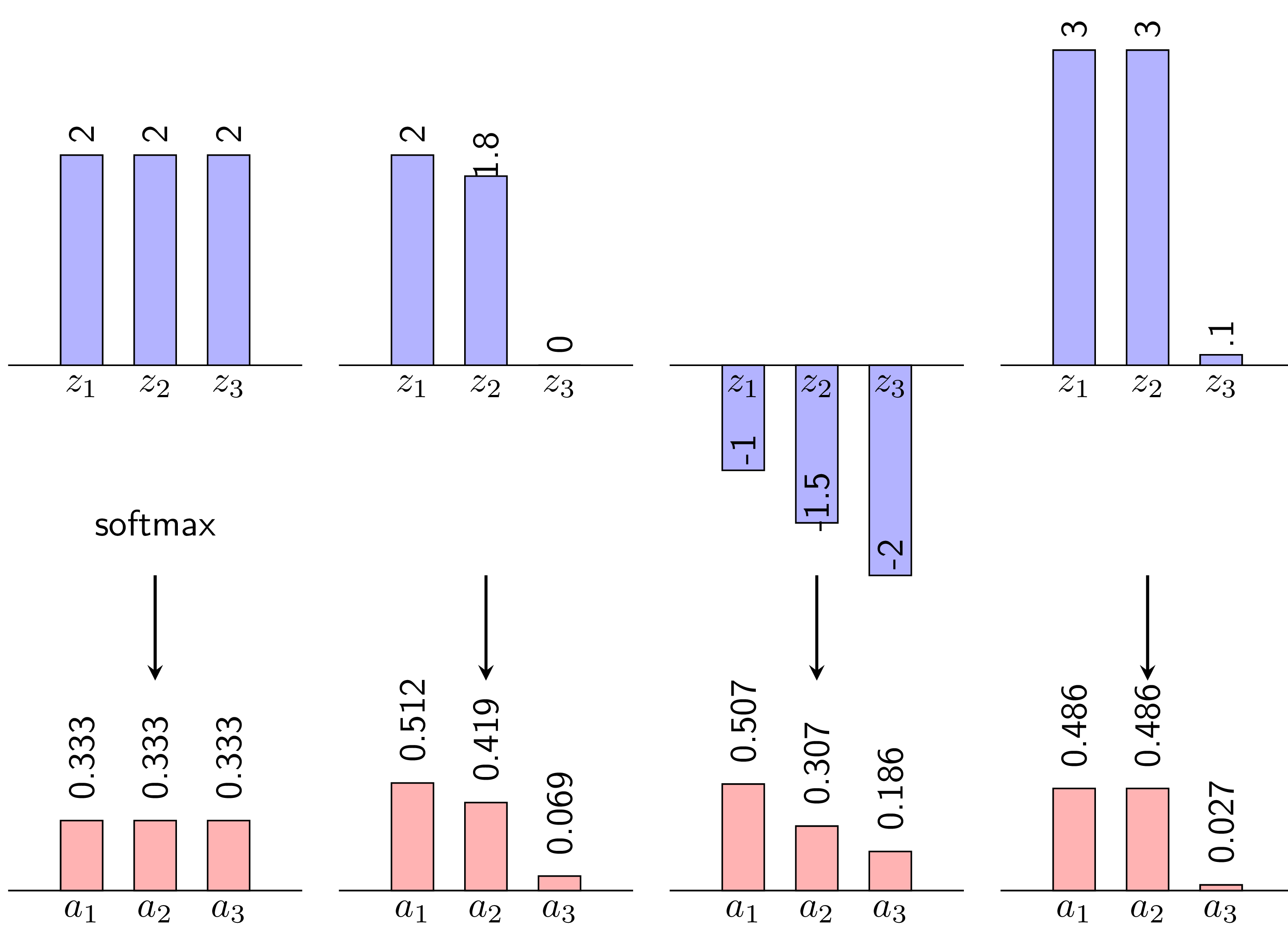
trong đó là logit cho lớp
ivà mẫu số tổng hợp trên tất cả các lớp.
Quá Trình Truyền Thông và Lan Truyền Ngược
Lan truyền thuận (Feed Forward):
Đây là quá trình đầu tiên trong đó mạng nơ-ron xử lý dữ liệu đầu vào. Dữ liệu chảy từ lớp đầu vào qua các lớp ẩn, và mỗi nơ-ron tính toán đầu ra của nó dựa trên trọng số và hàm kích hoạt. Kết quả cuối cùng là dự đoán được thực hiện bởi lớp đầu ra.
Chúng ta có thể biểu diễn quá trình truyền tiến một cách toán học như sau:
Giả sử là khả tích Riemann. Giả sử là . Thì là liên tục, và tại mọi mà liên tục tại , khả vi tại với .
Trong đó:
- là độ kích hoạt của lớp
l - là tổng trọng số của các đầu vào đến lớp
l - và là trọng số và độ chệch của lớp
l - là hàm kích hoạt
- là đầu ra dự đoán
- là dữ liệu đầu vào
- là tổng số lớp trong mạng
- là chỉ số lớp
Lan Truyền Ngược:
Sau khi có được dự đoán, mô hình so sánh nó với giá trị thực và tính toán sai số bằng cách sử dụng hàm mất mát. Quá trình lan truyền ngược liên quan đến việc gửi sai số quay ngược qua mạng, từ các lớp đầu ra đến các lớp đầu vào. Trọng số của các nơ-ron được cập nhật dựa trên các đạo hàm của hàm mất mát, giúp giảm sai số trong các vòng huấn luyện tiếp theo.
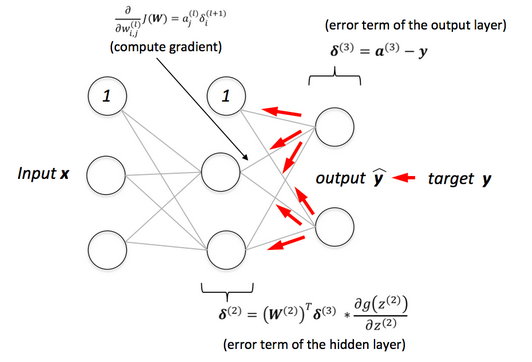
Giảm Gradient Ng��ẫu Nhiên (SGD)
Giảm Gradient Ngẫu Nhiên (SGD) là một kỹ thuật tối ưu hóa được sử dụng để tính toán các đạo hàm cho ma trận trọng số và độ chệch dựa trên một cặp dữ liệu huấn luyện . Để đơn giản hóa, giả sử đại diện cho một hàm mất mát liên quan đến cặp này, trong đó có thể là bất kỳ hàm mất mát nào, không giới hạn ở MSE (Mean Squared Error).
Đạo hàm của hàm mất mát đối với một trọng số cụ thể trong lớp cuối cùng có thể được biểu diễn như sau:
Ở đây, thường dễ dàng tính toán, và , vì .
Tương tự, đạo hàm của hàm mất mát với trọng số độ chệch trong lớp cuối cùng được cho bởi:
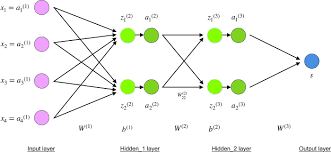
Để xác định các đạo hàm cho các trọng số trong các lớp trước đó, hãy xem cấu trúc như trong sơ đồ dưới đây. Ở đây, đầu vào z và đầu ra a của mỗi đơn vị được ghi rõ �để dễ hiểu. Đạo hàm có thể được tính toán như sau:
với
Phép tổng trong phương trình thứ hai xuất hiện vì (a^l_j) ảnh hưởng đến việc tính toán tất cả các , với . Đạo hàm bên ngoài dấu ngoặc nhấn mạnh rằng .
Từ quá trình này, rõ ràng là việc tính toán là rất quan trọng. Hơn nữa, để xác định các giá trị này, cần tính toán từ lớp đầu ra quay ngược đến lớp đầu vào. Quá trình tính toán quay ngược này tạo ra thuật ngữ "lan truyền ngược."
Tóm lại, việc tính toán đạo hàm trong SGD có thể được tóm tắt như sau:
- Tính toán các đạo hàm bằng cách sử dụng lan truyền ngược.
- Cập nhật các tham số mô hình dựa trên các đạo hàm đã tính toán và tỷ lệ học.
Cách tiếp cận này đảm bảo huấn luyện hiệu quả các mô hình trong khi xử lý các cập nhật ngẫu nhiên một cách hiệu quả.
Tiếp theo, chúng ta sẽ đi sâu vào khái niệm lan truyền ngược (backpropagation) một cách chi tiết hơn, khám phá cách mà các lỗi được lan truyền qua mạng và cách các trọng số được cập nhật để giảm thiểu các lỗi này.