Derivatives of all layers
Derivatives with Respect to Individual Parameters
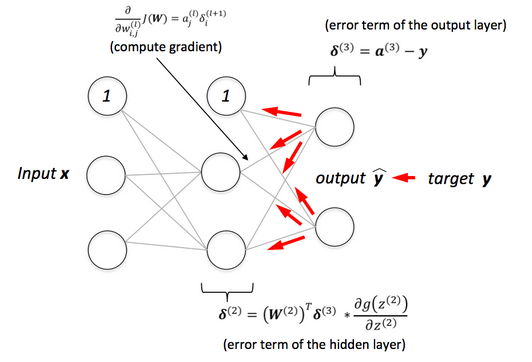
In feedforward step For a given input value xa^l$ at each layer are stored for later use.
For each unit j in the output layer, compute the error term:
From this, we can derive the following:
For layers , we compute:
Updating the derivatives for each parameter yields:
Derivatives with Respect to Matrices
The computation of derivatives for individual parameters as described above is useful for understanding the principles involved. However, in practice, we need to optimize the calculations by expressing them in vector and matrix forms to accelerate the algorithm. Let’s define:
Feedforward Step: For a given input value , compute the network output while storing the activations at each layer.
For the output layer, compute:
From this, we deduce:
For layers :
Here, denotes the element-wise product (Hadamard product), meaning each component of the two vectors is multiplied together to yield a resultant vector.
Updating the Derivatives for the Weight Matrices and Bias Vectors
Note: The expression for the derivative in the previous line might raise a question: why is it and not or others? A key rule to remember is that the dimensions of the two matrices on the right-hand side must match. Testing this reveals that the left-hand side represents the derivative with respect to , which has a dimension . Thus, and imply that the correct formulation must be . Additionally, the derivative with respect to a matrix of a scalar-valued function will have dimensions matching that of the matrix.
Backpropagation for Batch (Mini-Batch) Gradient Descent
What happens when we want to implement Batch or mini-batch Gradient Descent? In practice, mini-batch Gradient Descent is the most commonly used method. When the dataset is small, Batch Gradient Descent can be applied directly.
In this case, the pair ((X, Y)) will be in matrix form. Suppose that each computation iteration processes data points. Then, we have:
where is the dimension of the input data (excluding biases).
Consequently, the activations after each layer will have the following forms:
We can derive the update formulas as follows.
Feedforward Step: With a complete dataset (batch) or a mini-batch of input , compute the output of the network while storing the activations at each layer. Each column of corresponds to a data point in .
For the output layer, compute:
From this, we derive:
For layers :
Here, signifies the element-wise product, meaning each element of the two matrices is multiplied to produce a resultant matrix.
Updating the Derivatives for the Weight Matrices and Bias Vectors:
This structured approach to backpropagation for both stochastic and batch gradient descent not only enhances understanding but also optimizes the computational efficiency of neural network training.