Multi-Layer Perceptron (MLP)
Introduction to Artificial Neural Networks (ANN)
Artificial Neural Networks (ANN) are one of the foundational concepts in the fields of artificial intelligence (AI) and machine learning. Inspired by the structure and functioning of the human brain's nervous system, ANNs are computational models capable of learning from data and improving their performance over time. They have become the backbone of many modern technologies, including image recognition, natural language processing, and autonomous vehicles.
Origins of Artificial Neural Networks
The concept of ANN originated from the functioning of biological neurons in the human brain. The first artificial neuron model, known as the "Perceptron," was developed in 1958 by scientist Frank Rosenblatt. Although the initial Perceptron could only solve linear problems, it paved the way for the exploration of more complex models, leading to the development of multi-layer networks and modern deep learning algorithms.
Problem Statement Addressed by ANN
ANNs are commonly applied to problems involving classification, prediction, and pattern recognition. A typical problem that ANNs tackle is image classification: the system learns from labeled images and subsequently predicts the labels of new images. ANNs are also utilized in optimization tasks, regression analysis, and time series forecasting.
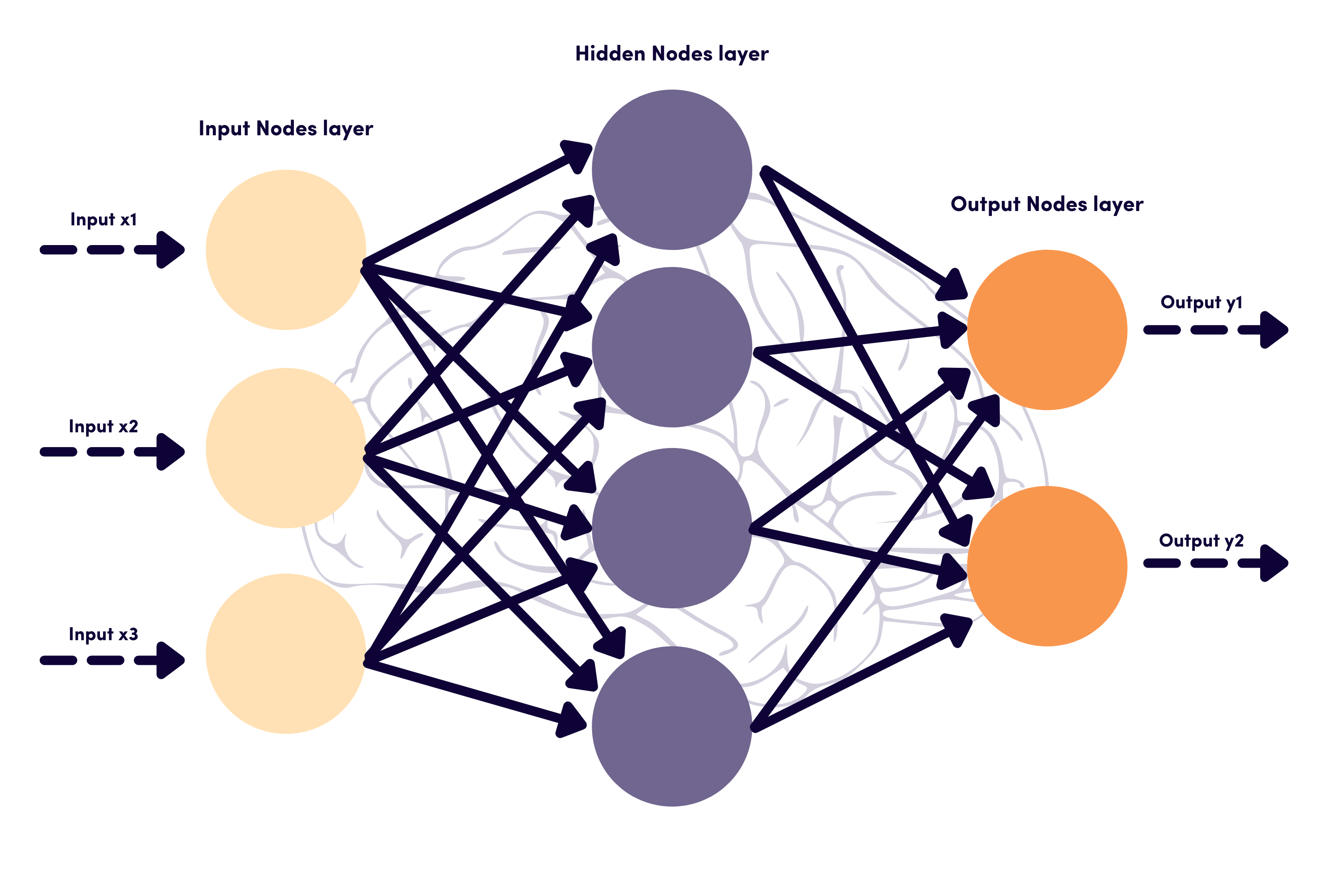
Layers in ANN
An Artificial Neural Network consists of multiple layers that work together to process and extract information from data:
-
Input Layer: This is the first layer that receives input data. Each neuron in this layer represents a feature of the data.
-
Hidden Layer(s): One or more hidden layers lie between the input and output layers. These layers extract features from the data using activation functions like ReLU (Rectified Linear Unit) or Sigmoid.
-
Output Layer: The final layer produces the predicted results based on the information processed in the hidden layers. The number of neurons in this layer depends on the problem at hand (e.g., if the classification task has three categories, the output layer will contain three neurons).
Activation Functions in ANN
Activation functions play a crucial role in determining the output of neurons in ANN. Here are some common activation functions:
- ReLU (Rectified Linear Unit): The ReLU function is defined as
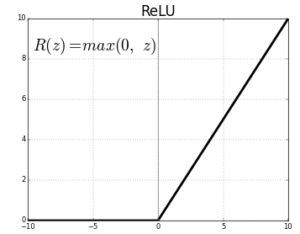
It is widely used in hidden layers due to its simplicity and effectiveness in mitigating the vanishing gradient problem. ReLU allows positive values to pass through while blocking negative values, leading to faster convergence during training.
- Sigmoid: The Sigmoid function is defined as

It squashes input values to a range between 0 and 1, making it suitable for binary classification tasks. However, it can lead to vanishing gradients for large positive or negative inputs, which may hinder the learning process in deeper networks.
- Tanh (Hyperbolic Tangent): The Tanh function is defined as

It outputs values between -1 and 1, which helps in centering the data around zero. Tanh generally performs better than the Sigmoid function, as it mitigates the vanishing gradient problem to a greater extent.
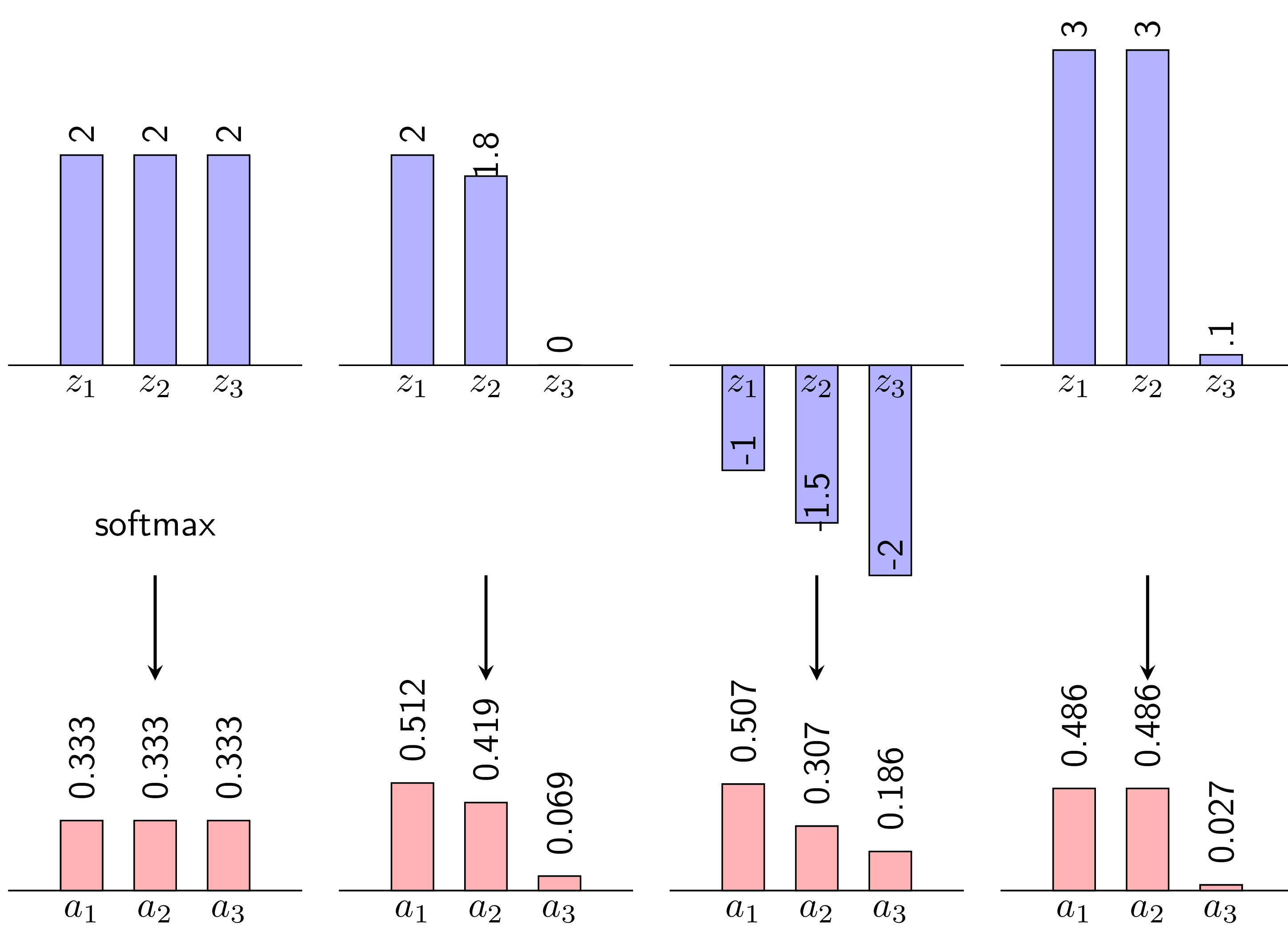
- Softmax: The Softmax function is typically used in the output layer of multi-class classification problems. It converts raw scores (logits) from the network into probabilities that sum to 1, making it suitable for models that need to predict the likelihood of each class. The formula for the Softmax function is given by:
where is the logit for class i and the denominator sums over all classes.
Feed Forward and Backpropagation Processes
Feed Forward
This is the initial process where the neural network processes input data. The data flows from the input layer through the hidden layers, and each neuron computes its output based on the weights and activation function. The final result is the prediction made by the output layer.
We can represent the feed forward process mathematically as follows:
where:
- is the activation of layer
l - is the weighted sum of inputs to layer
l - and are the weights and biases of layer
l - is the activation function
- is the predicted output
- is the input data
- is the total number of layers in the network
- is the layer index
Backpropagation
After obtaining the prediction, the model compares it with the actual value and calculates the error using the loss function. The backpropagation process involves sending the error backward through the network, from the output to the input layers. The weights of the neurons are updated based on the gradients of the loss function, which helps to reduce the error in future training iterations.
Stotastic Gradient Descent (SGD)
Stochastic Gradient Descent (SGD) is an optimization technique used to compute the gradients for weight matrices and biases based on a training data pair ((x, y)). To simplify, let (J) represent a loss function associated with this pair, where (J) can be any loss function, not limited to Mean Squared Error (MSE).
The derivative of the loss function concerning a specific weight in the final layer can be expressed as:
Here, is typically straightforward to calculate, and , as .
Similarly, the derivative of the loss function with respect to the bias in the final layer is given by:
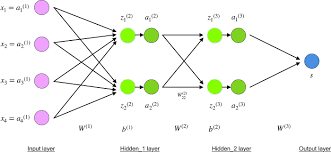
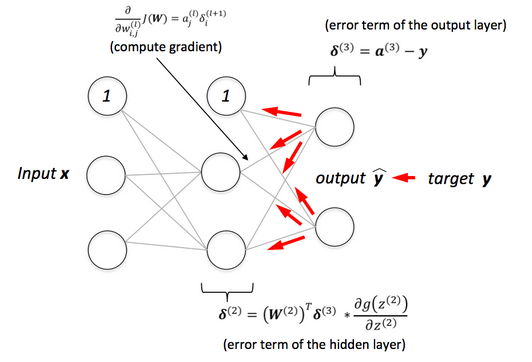
To derive gradients for weights in earlier layers, consider the structure shown in the diagram below. Here, each unit's input z and output a are explicitly labeled for clarity. The gradient can be computed as:
with
The summation in the second equation arises because influences the computation of all , where . The derivative outside the parentheses emphasizes that .
From this process, it's clear that calculating is crucial. Moreover, to derive these values, one must compute from the output layer back to the input layer. This backward computation gives rise to the term "backpropagation."
In summary, the calculation of derivatives in SGD can be succinctly outlined as follows:
- Compute gradients using backpropagation.
- Update model parameters based on the computed gradients and learning rate.
This approach ensures efficient training of models while handling stochastic updates effectively.
Next, we will delve into the concept of backpropagation in more detail, exploring how errors are propagated through the network and how weights are updated to minimize these errors.